介绍minigpt-4代码以及涉及到的语言模型和Blip-2
MiniGPT-4
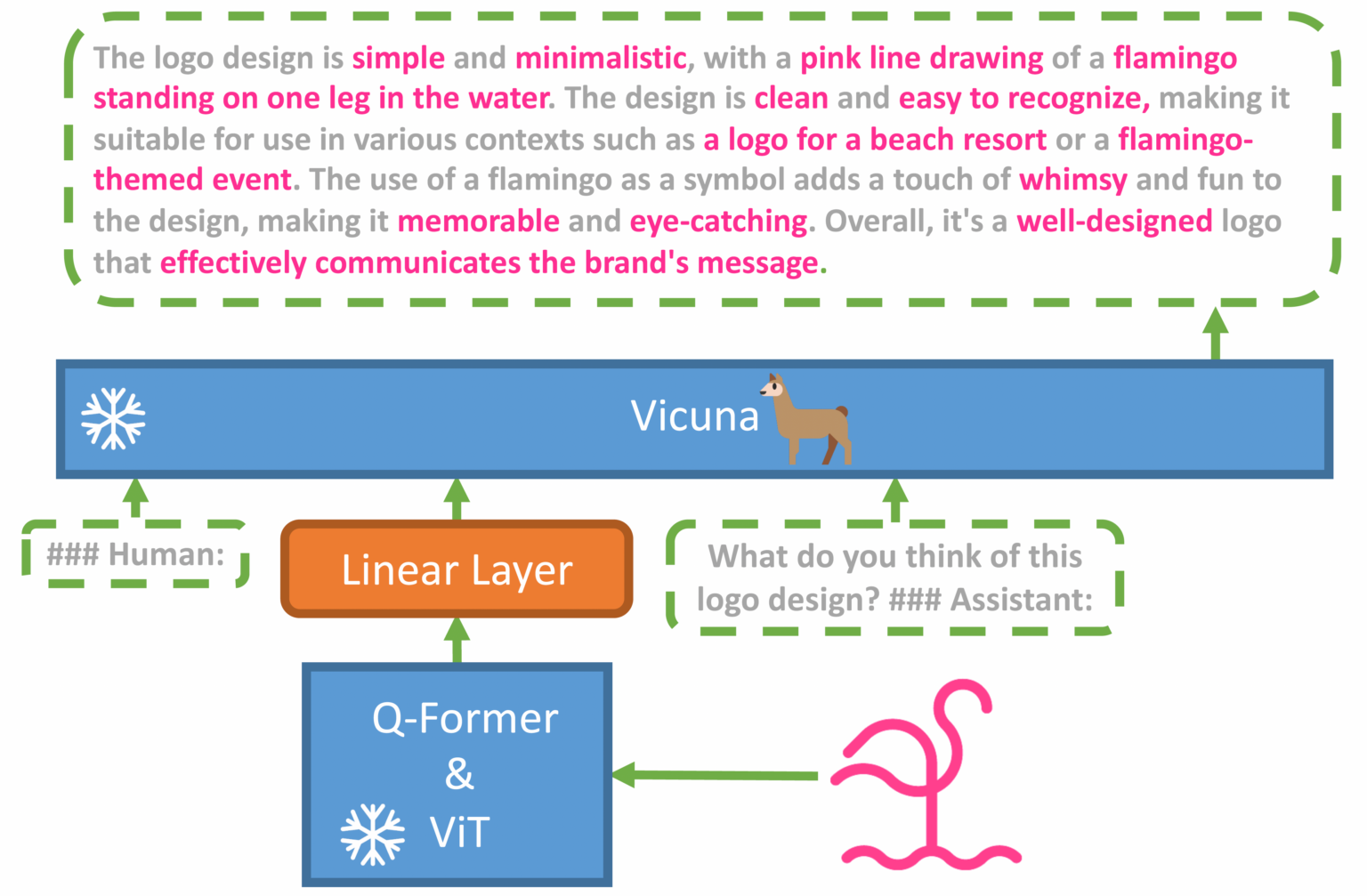
minigpt-4作为究极缝合怪,就是Blip-2的LLM换成了Vicuna,然后重新训练一下linear层,加上点工程的trick。其对应的模型结构不难理解,首先来看初始化部分,利用freeze的VIT、Q-Former以及LLAMA语言模型,其中加一个简单的线性映射保证维度一致。
加载VIT
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 print ('Loading VIT' )self.visual_encoder, self.ln_vision = self.init_vision_encoder( vit_model, img_size, drop_path_rate, use_grad_checkpoint, vit_precision ) if freeze_vit: for name, param in self.visual_encoder.named_parameters(): param.requires_grad = False self.visual_encoder = self.visual_encoder.eval () self.visual_encoder.train = disabled_train for name, param in self.ln_vision.named_parameters(): param.requires_grad = False self.ln_vision = self.ln_vision.eval () self.ln_vision.train = disabled_train logging.info("freeze vision encoder" ) print ('Loading VIT Done' )
接下来看init_vision_encoder这个函数,因为沿用的是BLIP-2的,所以选用的参数是eva的clip视觉编码器,eva这篇文章就是把掩码预训练在数量级上做到很大,然后下游迁移达到sota(这个名字很熟悉?没错,作者甚至用Asuka做头像,是个二次元)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 def init_vision_encoder ( cls, model_name, img_size, drop_path_rate, use_grad_checkpoint, precision assert model_name == "eva_clip_g" , "vit model must be eva_clip_g for current version of MiniGPT-4" visual_encoder = create_eva_vit_g( img_size, drop_path_rate, use_grad_checkpoint, precision ) ln_vision = LayerNorm(visual_encoder.num_features) return visual_encoder, ln_vision def create_eva_vit_g (img_size=224 ,drop_path_rate=0.4 ,use_checkpoint=False ,precision="fp16" ): model = VisionTransformer( img_size=img_size, patch_size=14 , use_mean_pooling=False , embed_dim=1408 , depth=39 , num_heads=1408 //88 , mlp_ratio=4.3637 , qkv_bias=True , drop_path_rate=drop_path_rate, norm_layer=partial(nn.LayerNorm, eps=1e-6 ), use_checkpoint=use_checkpoint, ) state_dict = torch.load('eva_vit_g.pth' , map_location="cpu" ) interpolate_pos_embed(model,state_dict) incompatible_keys = model.load_state_dict(state_dict, strict=False ) if precision == "fp16" : convert_weights_to_fp16(model) return model
和加载VIT很像,基本也是一致的:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 print ('Loading Q-Former' )self.Qformer, self.query_tokens = self.init_Qformer( num_query_token, self.visual_encoder.num_features ) self.Qformer.cls = None self.Qformer.bert.embeddings.word_embeddings = None self.Qformer.bert.embeddings.position_embeddings = None for layer in self.Qformer.bert.encoder.layer: layer.output = None layer.intermediate = None self.load_from_pretrained(url_or_filename=q_former_model) if freeze_qformer: for name, param in self.Qformer.named_parameters(): param.requires_grad = False self.Qformer = self.Qformer.eval () self.Qformer.train = disabled_train self.query_tokens.requires_grad = False logging.info("freeze Qformer" ) print ('Loading Q-Former Done' )
未完~先鸽
加载LLM
训练
引用:小小将知乎 https://zhuanlan.zhihu.com/p/624336159
要注意的是,MiniGPT-4这里不仅冻结了Vicuna模型,而且冻结了Q-Former,所以训练参数只剩下一个Linear Layer 了。那么重点就是MiniGPT-4是怎么训练的 ,或者说MiniGPT-4采用了什么样的数据来进行训练 。当然,MiniGPT-4也可以简单地像BLIP-2那样采用图像文本对来训练,但是实验发现了这样效果并不太好。 相比BLIP-2,MiniGPT-4采用了两阶段的训练策略,这个两阶段和BLIP-2不太一样,其实BLIP-2的第一阶段只是为了得到初步的Q-Former,并没有涉及LLM。 MiniGPT-4的第一阶段训练和BLIP-2的第二阶段一样(类似Flamingo),采用图像文本对数据集进行训练,训练目标是基于soft prompt来生成对应的文本描述,训练数据集是CC、SBU和LAION数据集中筛选的5M样本。完成这个阶段的训练后,虽然模型能够有一定的生成能力,但是它比较难产生连贯的语言,比如生成重复的单词或句子、零散的句子或不相关的内容。论文任务模型需要 instruction fine-tuning或者RLHF,这也是GPT-3到GPT-3.5进化的关键。 所以MiniGPT-4的第二阶段构建了一个高质量的图像文本数据集来进行finetune。首先从CC数据集中选择5000张图像,然后使用第一阶段训练好的模型来生成详细的文本描述,这里采用了如下所示的prompt来进行生成:
###Human : Describe this image in detail. Give as many details as possible. Say everything you see. ###Assistant:
但是这里生成的文本质量可能存在噪音或者错误,所以又基于ChatGPT来对生成的文本进行refine,这里采用的prompt是:
Fix the error in the given paragraph. Remove any repeating sentences, meaningless characters, not English sentences, and so on. Remove unnecessary repetition. Rewrite any incomplete sentences. Return directly the results without explanation. Return directly the input paragraph if it is already correct without explanation
另外为了保证数据质量,最后还是人工对ChatGPT美化后的文本进行检查,最终选出了大约3500个样本。然后基于这些样本进行第二阶段finetune,这里首先将数据集按照如下prompt构建:
###Human: ###Assistant:
这里的从一些预先定义好的模版中选取,比如“Describe this image in detail” 和 “Could you describe the contents of this image for me”。训练的优化目标就是根据prompt来生成对应的文本。论文里面说第二阶段的finetune非常高效,在batch=12下只需要训练400 steps就可以了。 经过第二阶段finetune的MiniGPT-4的生成效果就有明显改善,它不仅可以对图像生成详细的描述,也可以识别图像中有趣的地方,甚至发现图像中异常内容。


.png)








