
Multimodal NER
概述&原模型
写在开始
论文代码仓库:https://github.com/softhuafei/Pytorch-implementation-for-OCSGA
其实是少了object_label这个文件,需要翻历史记录下载,我也不到为啥把这个删了。
这应该是我第一次改论文代码,对于整体的代码框架啥的其实都不是很清楚,还有具体用到的一些方法,也不是特别熟,所以就来边学边改,做个记录。
----2022/5/30 update----
和博士师兄讨论完,感觉还是任重道远,bug确实不少,要弄的东西也蛮多的,所以既然这玩意不是只靠查查资料就能解决的,还是要静下心来,研读代码,毕竟这个代码也是挺规范的,还有很多地方值得学习,所以还是要耐住躁动和寂寞🚴♂️。
----2022/6/5 update----
哥们现在过拟合的问题还是没解决,感概良多,但是还是要踏踏实实地把这个东西做完,感觉心情失落是预期过高,对任务的分析不够客观,所以更需要静下心来调整分析。虽然说每天就答辩了,感觉具体的结果还是应该延期到交论文的时候提交,继续努力!
----2022/6/18 update—
由于这个课程结课延期,zxr终于获得了一线生机,然后这里来记录一下一些想法。
目前我想对于模型进行改进,但是又不知从何下手。
根据户老师所说的,要根据目标进行建模,根据问题特征来设计。这可能会涉及到对于数据的特征的提取,也就是对于数据的观察后,得出某种分布的hypothesis,或者是内部的某种relation,将这个insight应用于模型的构建中,但是问题在于,这样得到的结果可能是好的,也可能根本不起作用,而且这样的insight只是来自于后验的一部分观察,实际上和潜在的本质还是有不少差距的,就算是work了,怎么去证明是按照你设计的初衷work的,人面对deep NN这种复杂的模型,不能去完全用人为的特征限制,但是也要保证一定范围的可控,追求这种平衡是微妙的,也是有趣的。
对于神经网络的优化目标,是否可以定义为不让loss function卡在局部极值,而对于神经网络的解释性,可不可以理解为如何设计一种机制来做到将损失函数的空间转换成更加容易梯度下降的空间。其中的一种途径就是可以通过提取足够的特征,像MLP,其实可以喂给它不同类型的数据,理论上都是能逼近分布的,但是由于数据集的问题,可能学习一段时间就卡住了,这也说明在平时的应用中,MLP + Softmax的拟合往往是有限的。而CNN,Transformer其实都是先进行了提取特征的步骤,这其实是用一种弱机制去对输入的数据进行转换,得到相对来说最问题相关的部分,针对特定的问题,进行解决。
不可控性的来源应该是梯度下降这个方法,只是规定了要减少分布的差别,但是具体怎么做到的,是没有规定的,虽然可以探索人类未曾涉及的规律,但是这就会导致内部的隐状态和机制有些不可解释,而提取特征的过程,是不是可以视为把评判的标准不只是用梯度下降纯粹向着目标,而是另外还要兼顾到一些信息的提取,也就是增强真正有效的信息。
对于神经网络的三层理解:
- 线性和非线性组合的迭代,数据空间变换的角度,这种视角是很局限的,不是一般适用的。
- 概率分布和函数的逼近,从理论角度理解神经网络的潜在拟合能力。
- 优化损失函数空间。
Good idea和idea work之间的联系?
个人感觉,人总是去观察数据内在的某种联系和因果,这样得到某些规律,然后把这种规律作为motivation对模型加以改进,在loss function的空间上可能体现为选取了潜在更好的一块空间,把不太可能的部分省去。因为数据集和模型的复杂性,没办法提前证明这种idea的准确性,只能通过结果体现。一般来说,Good idea都是对于特定问题而言的,这里先不考虑普适的性质,对于特定的问题,实际上是用某种规则去进行弱的约束,感觉有点像黑盒里的东西变了一下,但是你也不知道能不能行,对于规律这种东西,理论上MLP都能学,但是介于实际问题中的复杂性,就很难达到那种效果了,这时候人为的一些idea是能更好的去协助模型学习,所以本质的假设还是人脑可以正确地理解问题。
所以感觉就有点玄学了,毕竟不是可以理论证明的东西,但是却可以从实践中一点点感知。物理这种就是根据某些假设先证明再检验,而DP就是先由某些假设实验再去理解,最终work的原因也可能是多样的,耦合的因素很多,很少有理论证明的部分。
首先从main.py开始
main.py的if __name__ == '__main__':开始看,
1 | if __name__ == '__main__': |
首先是一个parser = argparse.ArgumentParser(description='Tuning with NCRF++'),这个可以理解为存一些参数的容器,特点是,这个是通过命令行来进行对参数的赋值。
1 | # demo.py |
1 | python demo.py --str_arg = "lalala" |
接下来会碰到data,这玩意其实是data.py里定义的Data类的实例,这个Data类负责的是模型的参数和数据,这里列举一些包含的内容(只是一部分):
1 | self.model_name = None |
接下来是开始判断config文件是否为空,如果是空的,那就把args容器里面的默认值,赋值给data的成员变量,比如data.train_dir这些。如果config不是空就直接调用data.read_config(config),这个就是直接把config文件里面的参数对应读进data的参数,具体的话是先把config内容转换成字典,是用data中的config_file_to_dict函数。
接下来就是训练or解码的部分了,以train为例,
1 | if status == 'train': |
词表构建啥的细节后面的Chapter会细琐,构建完词表然后是去了generate_instance这个函数,这个函数是和batch划分和decode写文件有关的,这里给出得到的结果的展示,其实就是把所有信息整合起来。
1 | self.train_texts[0] |
然后预处理弄完了,就直接进入训练函数train了。
首先先要处理的就是划分batch,具体来说是这样的,划分一下batch的start和end然后对train_Ids去slice就行了:
1 | batch_size = data.HP_batch_size |
然后看batchify_with_label这个函数:
1 | def batchify_with_label(input_batch_list, gpu, if_train=True, sentence_classification=False, max_object_nb=0): |
实际上还要去看batchify_sequence_labeling_with_label函数(截取了一部分):
1 | def batchify_sequence_labeling_with_label(input_batch_list, gpu, if_train=True, max_object_nb=0): |
1 | Ouput of batch_word |
看到这个'cuda:0'真滴是非常的羡慕啊,不会出bug,然后就看了一下源码,是这样处理的,其实就是加个gpu判断然后cuda():
1 | if gpu: |
然后接下来其实就是把这些batch input喂给模型,就可以去训练了。
这里还是要提一句,这个cuda报错的问题要怎么去避免,因为默认tensor都是放到cpu上的:
1 | if data.HP_gpu: |
其实train的结构算是比较简单的,就是设置了epoch iteration的数量去循环,1个epoch是指把整个训练集过一遍,1个epoch内,是需要进行相应的batch iteration的,其实也就是对train_size // batch_size这么多组batch进行循环,同时计算loss并反向传播更新。
1 | model.train() |
里面还有个evaluate的部分,这部分会单独拿出来说,因为之前在这里遇到了bug。
然后这样的话,大致算是过了一遍流程,接下来的Chapter会细致的解析。
整体架构
如何创建一个工程
这部分改编自link
大体的目录如下(不是全部):
1 | ├── checkpoints/ |
其中:
checkpoints/: 用于保存训练好的模型,可使程序在异常退出后仍能重新载入模型,恢复训练data/:数据相关操作,包括数据预处理、dataset实现等models/:模型定义,可以有多个模型,例如上面的crf和MUL_LSTM_MCA,一个模型对应一个文件utils/:可能用到的工具函数,在这个项目中主要是封装了词表的一些相关函数。config.py:配置文件,所有可配置的变量都集中在此,并提供默认值main.py:主文件,训练和测试程序的入口,可通过不同的命令来指定不同的操作和参数requirements.txt:程序依赖的第三方库README.md:提供程序的必要说明
数据加载
这部分要看具体的任务,还要看提供的数据集格式,有时候数据集是划分好的,有时候是要自己去划分验证集、测试集的。这里还可以用到torchtext啥的,有机会会细琐,但是应该不是在这篇文章里。
我举个栗子,比如这种文本分类的处理,就是tokenize再构建vocab再去构建embedding,而对于NER,还要考虑label啥的,细节是有些不一样,但是还是有很多共同的地方,这个先鸽一下,项目做多了就回来总结。
关于_init_.py
可以看到,几乎每个文件夹下都有__init__.py,一个目录如果包含了__init__.py 文件,那么它就变成了一个包(package)。__init__.py可以为空,也可以定义包的属性和方法,但其必须存在,其它程序才能从这个目录中导入相应的模块或函数。例如在data/文件夹下有__init__.py,则在main.py 中就可以from data.dataset import DogCat。而如果在__init__.py中写入from .dataset import DogCat,则在main.py中就可以直接写为:from data import DogCat,或者import data; dataset = data.DogCat,相比于from data.dataset import DogCat更加便捷。
模型
这个搭模型,个人感觉相对来说比较简单,毕竟整体来看就和搭积木一样,把输入输出维度弄好,调调库就直接解决。
但是捏,像bert这种预训练模型,我之前没接触过,所以刚开始只知道一个hugggingface,不知道具体怎么去用bert,这里详细记录一下。
直接import bert的包是不够的,还有config和参数加载的过程:
1 | import transformers |
这上面的config.json和pytorch_model.bin是要去抱抱脸下的,link在这里bert_based_cased。
BiLSTM就蒜了,没啥可说的了,调调库就完事,原本是不准备讲的,但是由于改模型的时候卡bug了,改动的就是这块,不改的话是妹有问题的,所以还是有必要看看。
1 | # char -> emb -> drop |
1 | text_feat: |
这里再说一个crf,以前也就是知道维特比算法,然后具体crf怎么和神经网络结合的基本没了解过,这里以pytorch官方文档和本模型的代码做个较为细致的解读。
原理的部分看这个: https://www.zhihu.com/question/316740909/answer/2380526295
补充概率图模型大致介绍:
https://www.cnblogs.com/jiangkejie/p/10729773.html
https://blog.csdn.net/weixin_44441131/article/details/104434297
然后接下来是pytorch官方bilstm + crf代码的分析,可以看这个:
主要对本模型中crf分析如下:
这里提一下模型的习惯的构建方式:
在models/__init__py中,代码如下:
1 | from model.MUL_LSTM_MCA import * |
这样在主函数中就可以写成:
1 | from models import MUL_LSTM_MCA |
最后一种写法蛮重要的,可能之前都没接触过,但却是最常用的。
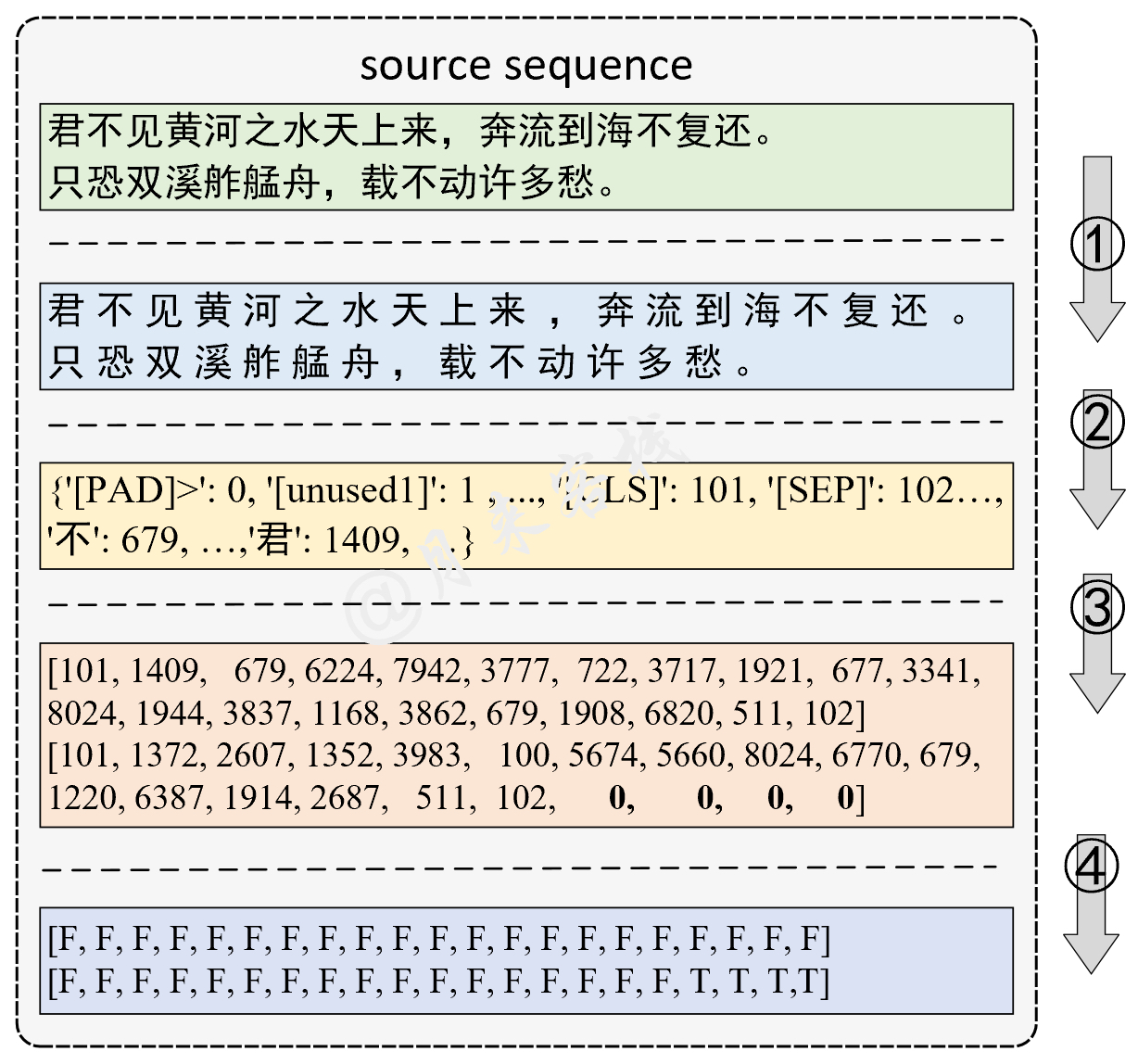
数据处理
Alphabet构建
先放张数据集的样式:
1 | IMGID:1015799 |
然后构建词表,这里是分成两种形式去处理,但实际中是CoNLL 2003这种,所以sentence_classification这种format就不说了。也比较容易理解,先去判断if len(line.strip().split('\t')) >= 2,也就是选取word label这种行,然后再分割出这两部分,分别加到word_alphabet和label_alphabet,提一下这里的feature其实应该是sentence_classification的那个POS这种标记符,这方便处理可以不考虑。
Alphabet类
1 | """ |
data里面的build_alphabet函数
1 | def build_alphabet(self, input_file): |
Embedding构建
首先需要说明的一点是,embedding和alphabet的index一定要是对应关系,也就是说如果选择用glove embedding,就要构建相应index的dictionary,如果选用bert的话同理,然后再利用训练集构建的词表和这个embedding字典(bert的话有embedding layer不用考虑)去构建输入的词向量。
原模型采用的是glove200词向量,也就是glove.twitter.27B.200d.txt,这个embedding的内容如下:

说的通俗易懂一点就是建立一个dictionary,key是首位的单词,value是对应的词向量,构建过程如下:
1 | def load_pretrain_emb(embedding_path): |
然后是再利用自己构建的词表来创建输入的向量,算是比较巧妙的一种方法,利用自己构建词表index->word,借助embedding字典word->embedding,然后直接变成index->embedding,这也和glove本身的性质有关,也就是word embedding pair,换成bert的话,就要利用它自带的词表index,不然和预训练的embedding不会对应。
1 | def build_pretrain_embedding(embedding_path, word_alphabet, embedd_dim=100, norm=True): |
模型训练&评估
改模型
词表处理
首先就是对词表的重写,因为是要用不同的embedding,由于BERT预训练模型中已经有了一个给定的词表(vocab.txt),因此并不需要根据自己的语料来建立一个词表。当然,也不能够根据自己的语料来建立词表,因为相同的字在我们自己构建的词表中和vocab.txt中的索引顺序肯定会不一样。然后是要利用这个索引作为输入喂到BERT里。
具体做法就是把build_alphabet给改了,改后如下:
1 | def build_label_alphabet(self, input_file): |
其实就是加了个bulid_word_alphabet,对BERT的vocab.txt去处理,这里用了自己写的Alphabet类,是挺方便的。然后再把有关char的部分全删掉,还有原本word embedding的构建。
但是嗷,这样配合下面的模型替换后,实际的效果并不是很理想,考虑是分词的原因,因为bert的tokenizers会把word还要划分,所以其实直接那种整个单词的输入可能是有点问题的,接下来是利用huggingface中的tokenizer分词:
模型更换
大致分为两块,第一是不加object_feature直接把char-Bilstm换成bert,第二就是再在这个基础上,去加上visual的信息,做一个多模态的NER。
其实也是因为俺之前没用过
bert,然后这第一次用就卡了挺多bug的,所以准备把改模型的工作划分成阶段性,减少错误的耦合。
替换为Bert
模型改为以下:
1 | import transformers |
或者是用distilbert-base-cased,也就是蒸馏过的,效果确实好,跑的又快又好,改动如下:
1 | import transformers |
加入多模态信息
这个要考虑的点应该还是有些的,比如object_feature的embedding选取,这个是否能直接也和bert的embedding选取一样还是要研究一下的,大致的思路先设成concat以后再去get fusion feature。
遇到的bug
colab打开文件
解决方法:用!cd不行的时候试试%cd
Torch Tensor放在GPU上
这个比较怪,有几种格式是不行的,需要注意一下
梯度NAN
这个可能是学习律没调好,可以参考一些资料,bert的话设置成1e-5 or 3e-5都是可以的。也就是
1 | optimizer = torch.optim.Adam(model.parameters(), lr=5e-5) |
p,r,f的值问题
会有值异常的情况,这里的
分别就是评测指标
,这个不熟的话可以看下面的资料:https://zhuanlan.zhihu.com/p/161703182
异常的原因是压根啥也没学到,可能是和学习率的设置有关,我就是因为学习率不对导致的这个问题。
Bert过拟合
可以看看下面的例子,训练集的f1score就很高,但是测试集就不行了。
1 | Epoch: 9 training finished. Time: 115.85s, speed: 34.53st/s, total loss: 11371.80078125 |
index越界
1 | Traceback (most recent call last): |
1 | Traceback (most recent call last): |

魔改的

原本的



.png)







