
nlp learning recording
nlp learning recording
General Procedure Of Preprocessing
- Normalization
- Tokenization
- Stop words
- Part-of-Speech Tagging
- Named Entity Recognition
- Stemming and Lemmatization
Word Embedding
One-hot Vector
Description: most simple way to represent categorical feature one-hot.
Disadvantages:
- For large vocabularies, these vectors will be very long: vector dimensionality is equal to the vocabulary size.
- These vectors know nothing about the words they represent, one-hot vectors do not capture meaning.
Improvement Motivation
To solve the semantics problem, we need to first define the notion of meaning that can be used in practice.
Distributional hypothesis: Words which frequently appear in similar contexts have similar meaning.
“You shall know a word by the company it keeps” with the reference to J. R. Firth in 1957
This is an extremely valuable idea: it can be used in practice to make word vectors capture their meaning.
According to the distributional hypothesis, “to capture meaning” and “to capture contexts” are inherently the same. Therefore, all we need to do is to put information about word contexts into word representation.
Main idea: We need to put information about word contexts into word representation.
Count-Based Methods
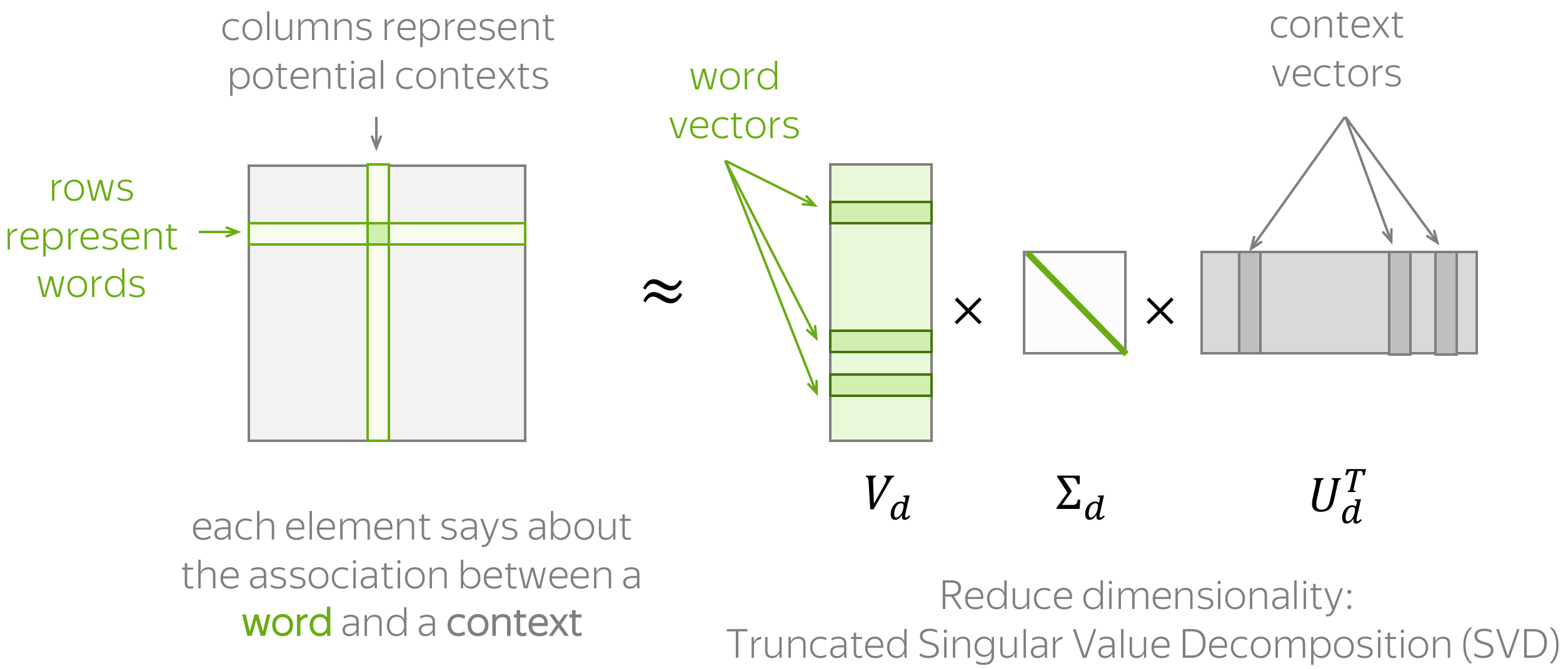
Main idea: We have to put information about contexts into word vectors.
How: Put this information manually based on global corpus statistics.
general procedure:
- construct a word-context matrix
- reduce its dimensionality
To estimate similarity between words/contexts, usually you need to evaluate the dot-product of normalized word/context vectors (i.e., cosine similarity).
To define a count-based method, we need to define two things:
- possible contexts (including what does it mean that a word appears in a context),
- the notion of association, i.e., formulas for computing matrix elements.
Simple: Co-Occurence Counts
-
Context: surrounding words in a L-sized window.
-
Matrix element:
- number of times word w appears in context c.
Positive Pointwise Mutual Information (PPMI)
-
Context: surrounding words in a L-sized window.
-
Matrix element:
where
SUM:
- Rely on matrix factorization (e.g. LSA, HAL).
- While these methods effectively leverage global statistical information, they are primarily used to capture word similarities and do poorly on tasks such as word analogy, indicating a sub-optimal vector space structure
Reference papers/Notes/Blogs:
http://web.stanford.edu/class/cs224n/readings/cs224n-2019-notes01-wordvecs1.pdf
Word2Vec
Let us remember our main idea again:
Main idea: We have to put information about contexts into word vectors.
While count-based methods took this idea quite literally, Word2Vec uses it in a different manner:
How: Learn word vectors by teaching them to predict contexts.
Intuition: Why we choose this kind of structure to build the word embedding?
In fact, we are constructing a dimension reduction method that builds in our insights(distributional hypothesis).
Let’s first look at t-SNE method:
t-SNE preserves the original data structure by modeling distance to probability distribution.
Word2Vec wants to construct a embedding space structure in a lower dimension.
The structure is actually the target probability distribution, instead of just having the original data distribution, in nlp, we can have our target probability distribution using based on the hypothesis. The way t-SNE calculate the similarity is to use the Gaussian distribution over the Euclidean distance, while Word2Vec uses cosine similarity.
Weight tying is such a method use the idea kind of like Word2Vec.
Word2Vec is a model whose parameters are word vectors. These parameters are optimized iteratively for a certain objective.
The objective forces word vectors to “know” contexts a word can appear in: the vectors are trained to predict possible contexts of the corresponding words.
Due to the distributional hypothesis, if vectors “know” about contexts, they “know” word meaning.
- Learned parameters: word vectors
- Goal: make each vector “know” about the contexts of its word.
- How: train vectors to predict possible contexts from words(or words from contexts)
Word2Vec is an iterative method. Its main idea is as follows:
- take a huge text corpus;
- go over the text with a sliding window, moving one word at a time. At each step, there is a central word and context words (other words in this window);
- for the central word, compute probabilities of context words;
- adjust the vectors to increase these probabilities.
For the detail of CBOW and Skip-Gram, just see the following papers:
https://arxiv.org/pdf/1411.2738v4.pdf
http://web.stanford.edu/class/cs224n/readings/cs224n-2019-notes01-wordvecs1.pdf
The model explanation:
-
Weight matrix: learned word/context representations.
-
Dot product: measure the similarity.
The reason why we just use the first matrix as the representation of word embedding.
https://blog.csdn.net/weixin_42279926/article/details/106403211
https://stackoverflow.com/questions/29381505/why-does-word2vec-use-2-representations-for-each-word
Improvement Motivation
Note that the summation over is computationally huge! Any update we do or evaluation of the objective function would take
time which if we recall is in the millions.
Negative Sampling
- context vectors not for all words, but only with a subset of K “negative” examples
- New Objective function using sigmoid
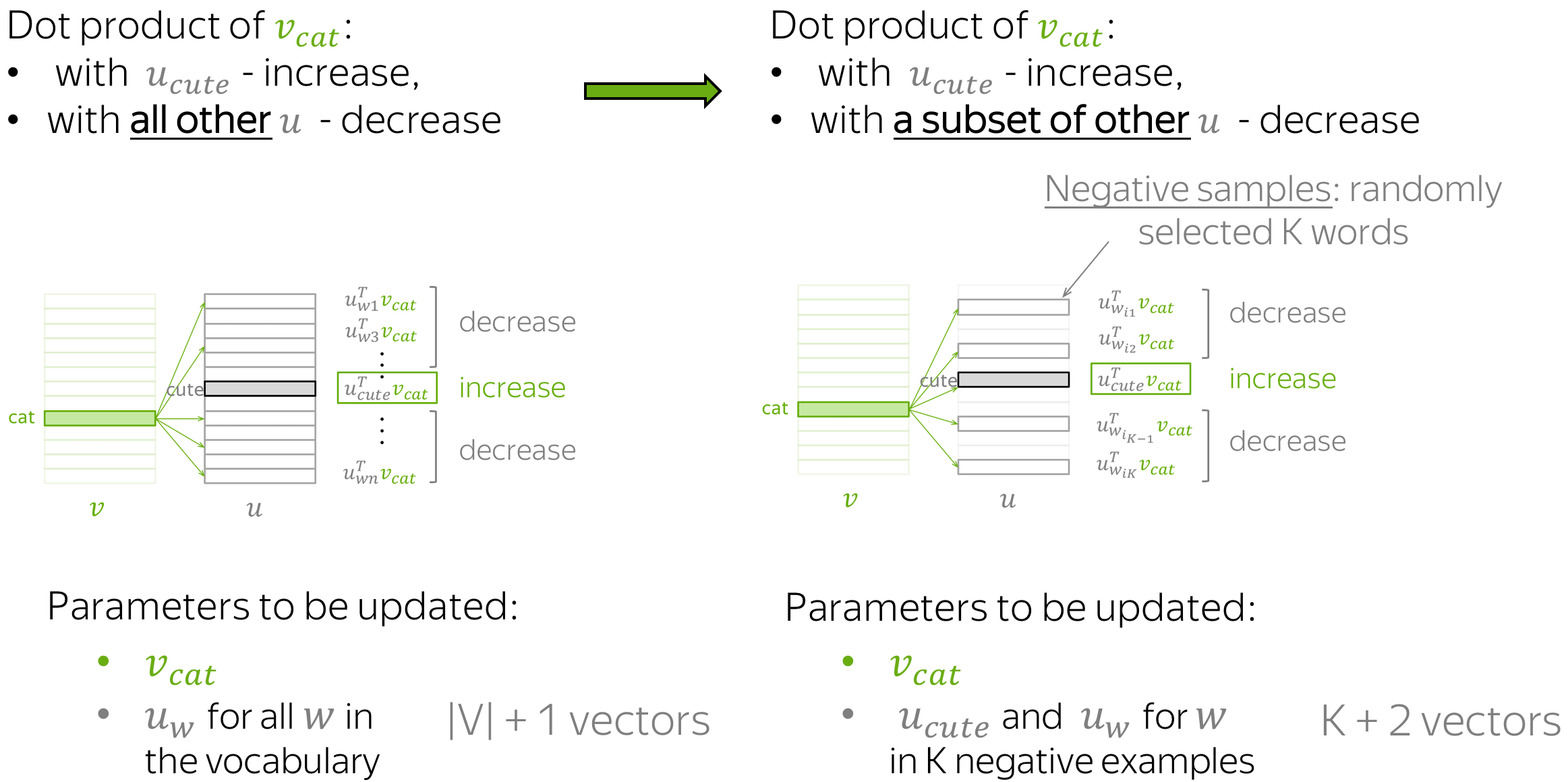 $$
J=-\sum_{(w, c) \in D} \log \frac{1}{1+\exp \left(-u_{w}^{T} v_{c}\right)}-\sum_{(w, c) \in \tilde{D}} \log \left(\frac{1}{1+\exp \left(u_{w}^{T} v_{c}\right)}\right)
$$
$$
J=-\sum_{(w, c) \in D} \log \frac{1}{1+\exp \left(-u_{w}^{T} v_{c}\right)}-\sum_{(w, c) \in \tilde{D}} \log \left(\frac{1}{1+\exp \left(u_{w}^{T} v_{c}\right)}\right)
$$
Hierarchical Softmax
Hierarchical Softmax uses a binary tree where leaves are the words. The probability of a word being the output word is defined as the probability of a random walk from the root to that word’s leaf. Computational cost becomes instead of
.
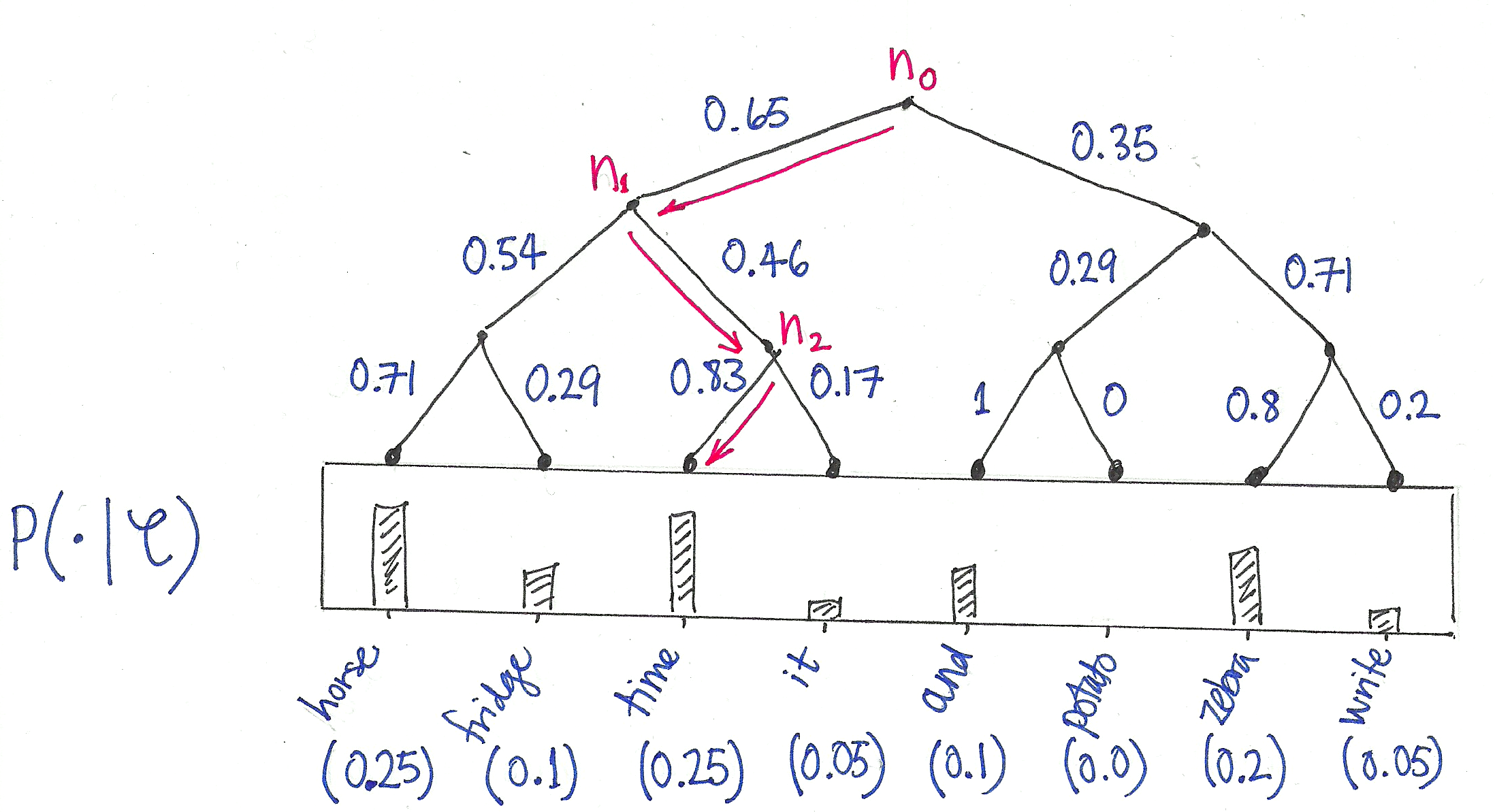
Sum:
Reference papers/Notes/Blogs:
word2vec Parameter Learning Explained
Hierarchical Softmax – Building Babylon (building-babylon.net)
Glove
Evaluation of Word Embeddings
Reference:
http://www.fanyeong.com/2018/02/19/glove-in-detail/
Text Classification
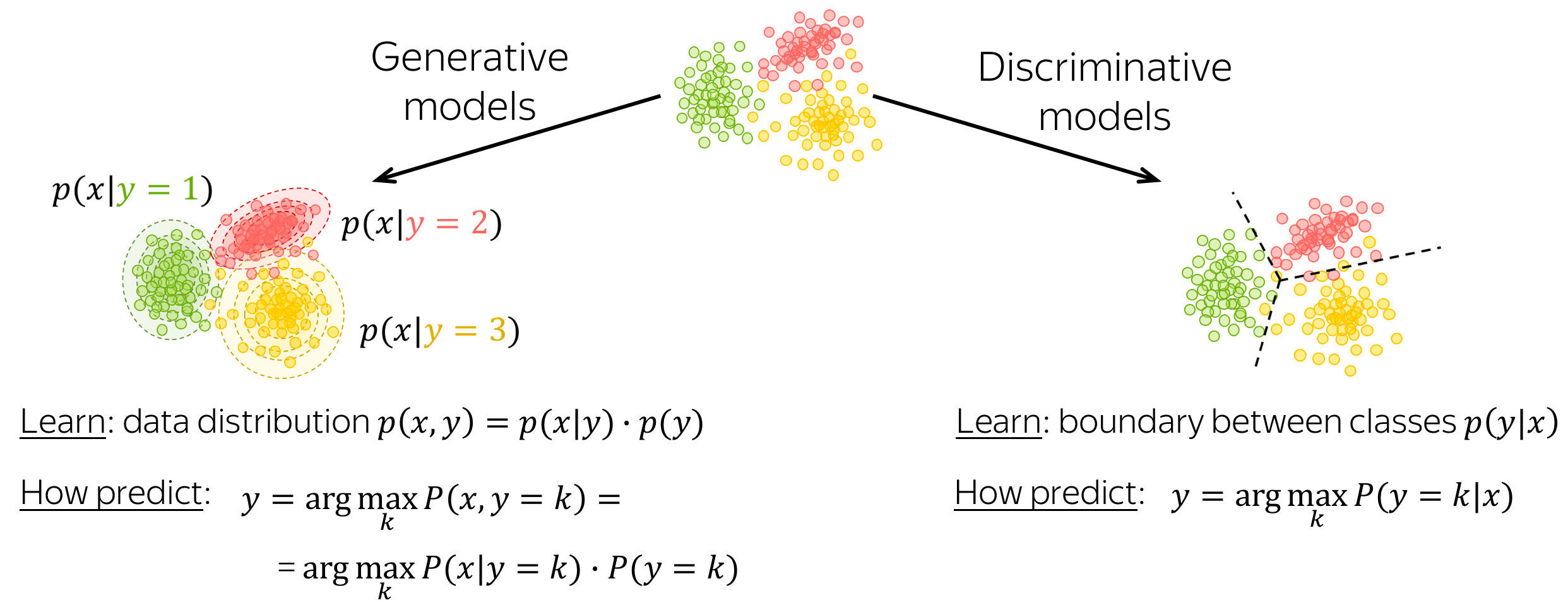
A classification model can be either generative or discriminative.
- generative models
Generative models learn joint probability distribution of data. To make a prediction given an input x, these models pick a class with the highest joint probability:
.
- discriminative models
Discriminative models are interested only in the conditional probability p(y|x), i.e. they learn only the border between classes. To make a prediction given an input x, these models pick a class with the highest conditional probability:.
Naive Bayes Classifier
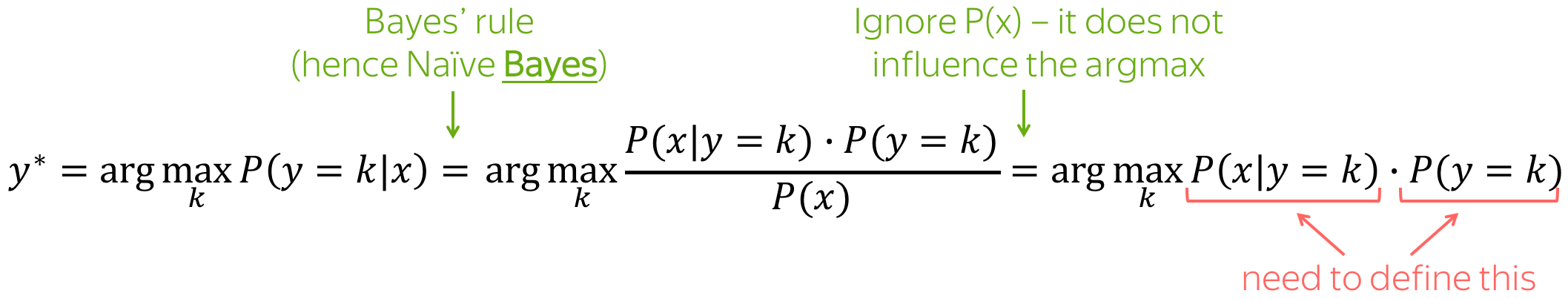
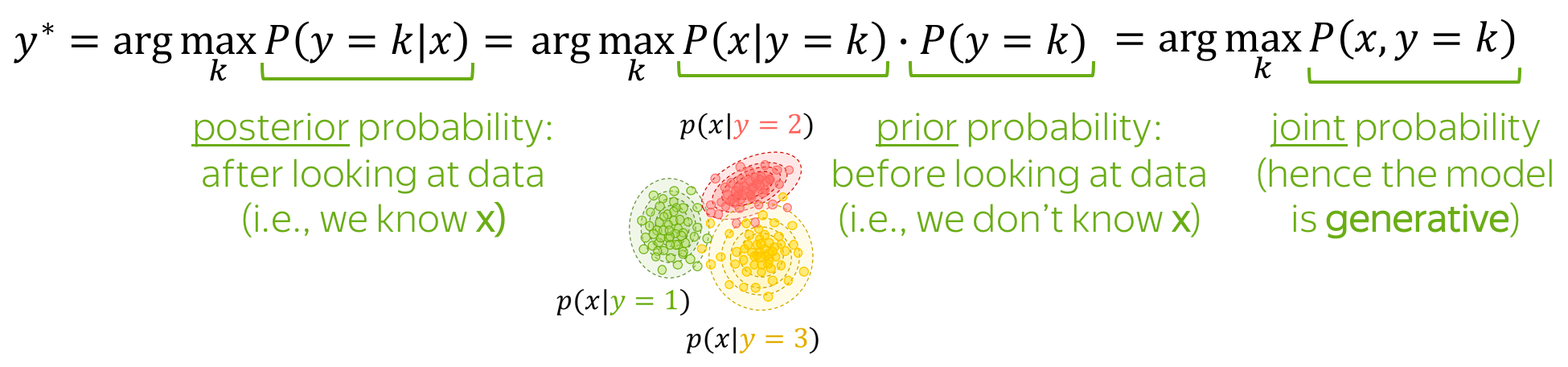
Maximum Entropy Classifier (aka Logistic Regression)
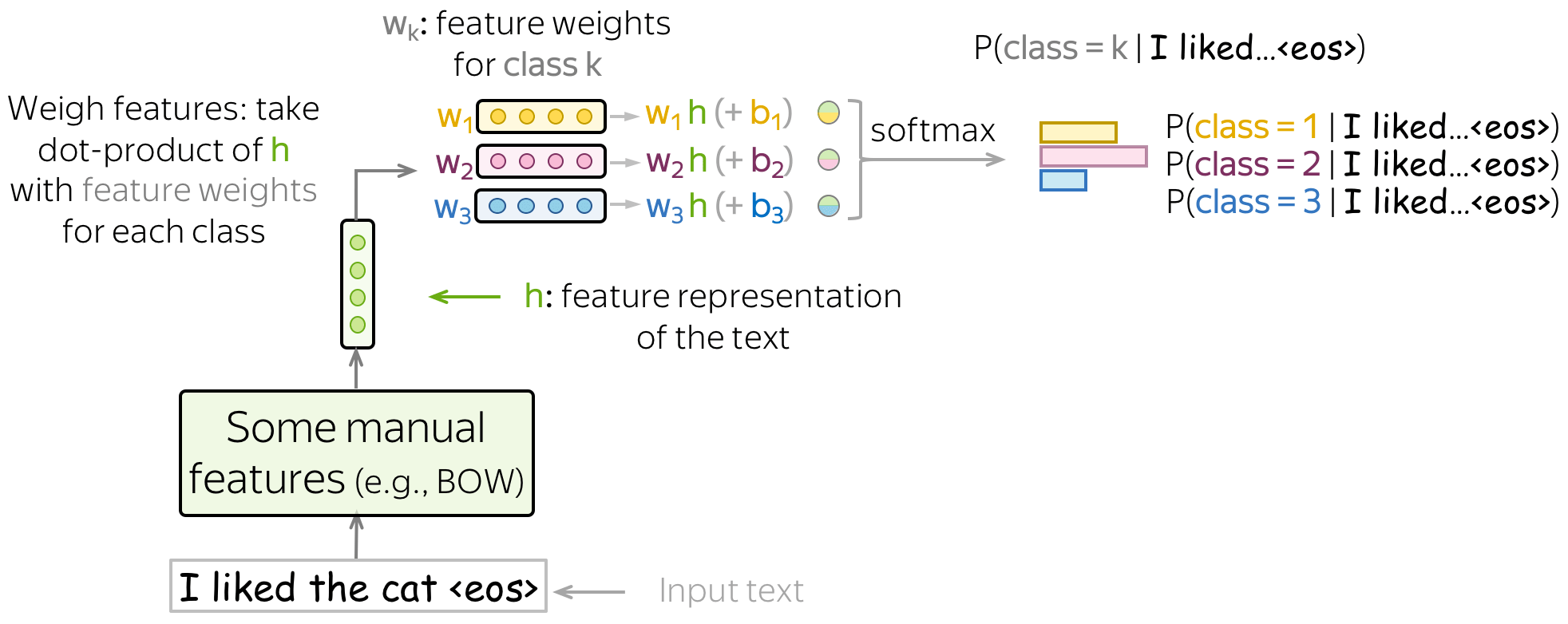
Text Classification with Neural Networks
SVM for Text Classification
Language Modeling
Seq2Seq and Attention
不足点:
RNN & LSTM
LSTM
Transformer
https://ruder.io/state-of-transfer-learning-in-nlp/
Transformer detailed understanding:
What’s the role of feed forward network
https://vaclavkosar.com/ml/Feed-Forward-Self-Attendion-Key-Value-Memory
Why we use the matrix
to get
The difference between BN and LN
Inductive bias
https://www.baeldung.com/cs/ml-inductive-bias#1-bayesian-models
Pytorch
Pytorch Basic
https://www.youtube.com/watch?v=x9JiIFvlUwk
tensor.data
reshape, view, transpose, permute
https://jdhao.github.io/2019/07/10/pytorch_view_reshape_transpose_permute/#view-vs-transpose-1
https://discuss.pytorch.org/t/difference-between-view-reshape-and-permute/54157/2
embedding layer
https://blog.csdn.net/sinat_40258777/article/details/122388863
Python global variable:
Python yield
https://blog.csdn.net/mieleizhi0522/article/details/82142856
Torchtext for nlp pre-process
https://www.youtube.com/watch?v=KRgq4VnCr7I
https://openbayes.com/console/open-tutorials/containers/M10lgtS5Dep
https://blog.csdn.net/nlpuser/article/details/88067167
https://zhuanlan.zhihu.com/p/397919716
Torchtext version problem
Project
BiLSTM + CRF
https://guillaumegenthial.github.io/sequence-tagging-with-tensorflow.html


.png)







