voidadd(int a, int b){ e[idx] = b, ne[idx] = h[a], h[a] = idx ++; }
intdfs(int u){ //其实就是利用dfs可以求子树长度这一性质,对每个节点遍历求max的子树长度,然后和全局最小ans比较 st[u] = true; int sum = 1, res = 0; for(int i = h[u]; i != -1; i = ne[i]){ int j = e[i]; if(!st[j]){ int s = dfs(j); res = max(res, s); sum += s; } } res = max(n - sum, res); //n-sum表示除了该节点和其字数外的分支 ans = min(ans, res); return sum; }
intmain(void){ memset(h, -1, sizeof h); cin >> n; for(int i = 0; i < n-1; i++){ int a, b; cin >> a >>b; add(a, b), add(b,a); } dfs(1); cout << ans << endl;
voidadd(int a, int b){ e[idx] = b, ne[idx] = h[a] ,h[a] = idx++; //建立邻接表的时候,用idx只是辅助建表,使用图的时候是不用idx的 }
intbfs(){ int hh=0, tt =0; q[0] = 1; d[1] = 0; while(hh <= tt){ int t = q[hh++]; for(int i = h[t]; i != -1; i = ne[i]){ int j = e[i]; if(d[j] == -1){ d[j] = d[t] + 1; q[++tt] = j; } } } return d[n]; }
intmain(void){ cin >> n >> m; memset(d, -1, sizeof d); memset(h, -1, sizeof h); int a, b; for(int i = 0; i < m ; i++){ cin >> a >> b; add(a,b); } cout << bfs() << endl; return0; }
int e[N], h[N], ne[N], idx; int q[N], d[N]; int n, m;
voidadd(int a, int b){ e[idx] = b, ne[idx] = h[a], h[a] = idx++; }
booltopsort(){ int hh = 0, tt = -1; for(int i = 1 ; i <= n; i++){ if(!d[i]) q[++tt] = i; } while(hh <= tt){ int t = q[hh++]; for(int i = h[t]; i != -1; i = ne[i]){ int j = e[i]; d[j]--; if(!d[j]) q[++tt] = j; } } return tt == n-1; }
intmain(void){ cin >> n >> m; memset(h, -1, sizeof h); memset(d, 0, sizeof d); for(int i = 0; i < m; i++){ int a, b; cin >> a >> b; add(a, b); d[b]++; } if(topsort()){ for(int i = 0; i < n; i++) printf("%d ",q[i]); //如果有拓扑序列的话,q[N]就是 } elseputs("-1"); return0; }
The longest possible shortest path from source to destination can have “stops”. According to Lemma 24.15 Path-relaxation property in CLRS, after each “relaxation” step, you get and this value remains unchanged ever since. So after times we must finish finding all results for a single-source shortest path problem. You make easily find a counterexample to say why loop for fewer than will fail to find all shortest paths.
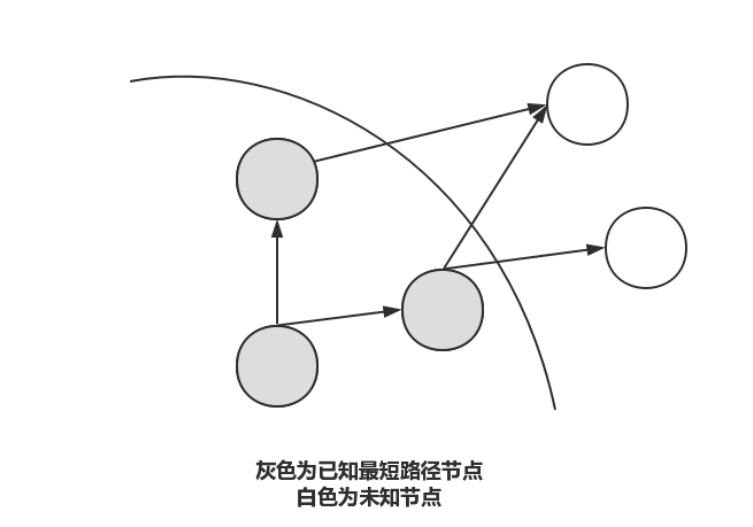
/*Dijkstra模板*/ intdijkstra(){ memset(dist, 03xf, siszeof dist);//dist[i] <- INF dist[1] = 0//dist[1] <- 0, for i from 1 to n t <- -1; //每次都要初始化t for j from 1 to n //把不在s中的距离最近的点赋值给t if(!st[j] && (t == -1 || dist[t] > dist[j]) ) t <- j; st[t] = true; //s <- t for j from 1 to n//用t更新其他点的距离 if(!st[j]) dist[j] = min(dist[j], dist[t] + g[t][j]); if(dist[n] == 0x3f3f3f3f) return-1; return dist[n]; } //ps:稠密图用邻接矩阵存
intmain(void){ cin >> n >> m; memset(g, 0x3f, sizeof g); for(int i = 0; i < m; i++){ int a, b, c; cin >> a >> b >> c; g[a][b] = min(g[a][b], c); //处理重边 } int t = dijkstra(); printf("%d ", t); return0; }
// 如果第n次迭代仍然会松弛三角不等式,就说明存在一条长度是n+1的最短路径,由抽屉原理,路径中至少存在两个相同的点,说明图中存在负权回路。 for (int i = 0; i < n; i ++ ) { for (int j = 0; j < m; j ++ ) { int a = edges[j].a, b = edges[j].b, w = edges[j].w; if (dist[b] > dist[a] + w) dist[b] = dist[a] + w; } }
if (dist[n] > 0x3f3f3f3f / 2) return-1; return dist[n]; }
int h[N], ne[N], e[N], idx, w[N]; int st[N], dist[N]; int n, m;
intspfa(){ queue<int> q; memset(dist, 0x3f, sizeof dist); dist[1] = 0; q.push(1); st[1] = true; while(q.size()){ int t = q.front(); q.pop(); st[t] = false; for(int i = h[t]; i != -1; i = ne[i]){ int j = e[i]; if(dist[j] > dist[t] + w[i]){ dist[j] = dist[t] + w[i]; if(!st[j]){ st[j] = true; q.push(j); } } } } return dist[n]; }
voidadd(int a, int b, int c){ e[idx] = b, ne[idx] = h[a], w[idx] = c, h[a] = idx++; }
intmain(void){ cin >> n >> m; memset(h , -1 , sizeof h); for(int i = 0; i < m; i++){ int a, b ,c; cin >> a >> b >>c; add(a, b ,c); } int t = spfa(); if(t == 0x3f3f3f3f) puts("impossible"); else cout << dist[n] << endl; return0; }
while(q.size()){ int t = q.front(); q.pop(); st[t] = false; for(int i = h[t]; i != -1; i = ne[i]){ int j = e[i]; if(dist[j] > dist[t] + w[i]){ dist[j] = dist[t] + w[i]; cnt[j] = cnt[t] + 1; if(cnt[j] >= n) returntrue; if(!st[j]){ st[j] = true; q.push(j); } } } } returnfalse; }
voidadd(int a, int b, int c){ e[idx] = b, ne[idx] = h[a], w[idx] = c, h[a] = idx++; }
intmain(void){ cin >> n >> m; memset(h , -1 , sizeof h); for(int i = 0; i < m; i++){ int a, b ,c; cin >> a >> b >>c; add(a, b ,c); } int t = spfa(); if(t == false) puts("No"); elseputs("Yes"); return0; }
Floyd
模板
1 2 3 4 5 6 7 8 9 10 11 12 13 14
//初始化: for (int i = 1; i <= n; i ++ ) for (int j = 1; j <= n; j ++ ) if (i == j) d[i][j] = 0; else d[i][j] = INF;
// 算法结束后,d[a][b]表示a到b的最短距离 voidfloyd() { for (int k = 1; k <= n; k ++ ) for (int i = 1; i <= n; i ++ ) for (int j = 1; j <= n; j ++ ) d[i][j] = min(d[i][j], d[i][k] + d[k][j]); }
int n; // n表示点数 int h[N], e[M], ne[M], idx; // 邻接表存储图 int color[N]; // 表示每个点的颜色,-1表示未染色,0表示白色,1表示黑色
// 参数:u表示当前节点,c表示当前点的颜色 booldfs(int u, int c) { color[u] = c; for (int i = h[u]; i != -1; i = ne[i]) { int j = e[i]; if (color[j] == -1) { if (!dfs(j, !c)) returnfalse; } elseif (color[j] == c) returnfalse; }
returntrue; }
boolcheck() { memset(color, -1, sizeof color); bool flag = true; for (int i = 1; i <= n; i ++ ) if (color[i] == -1) if (!dfs(i, 0)) { flag = false; break; } return flag; }
int n1, n2; // n1表示第一个集合中的点数,n2表示第二个集合中的点数 int h[N], e[M], ne[M], idx; // 邻接表存储所有边,匈牙利算法中只会用到从第一个集合指向第二个集合的边,所以这里只用存一个方向的边 int match[N]; // 存储第二个集合中的每个点当前匹配的第一个集合中的点是哪个 bool st[N]; // 表示第二个集合中的每个点是否已经被遍历过
boolfind(int x) { for (int i = h[x]; i != -1; i = ne[i]) { int j = e[i]; if (!st[j]) { st[j] = true; if (match[j] == 0 || find(match[j])) { match[j] = x; returntrue; } } }
returnfalse; }
// 求最大匹配数,依次枚举第一个集合中的每个点能否匹配第二个集合中的点 int res = 0; for (int i = 1; i <= n1; i ++ ) //这个注意要是从1开始的,不然match[0] = 0会出现bug { memset(st, false, sizeof st); if (find(i)) res ++ ; } //可能会问说不是两个集合的点么,下标怎么不区分,实际上可以这么理解,就是把刻板印象自环理解为两个标号相同的点连边,两个点分别位于两个集合,这样去理解是不冲突的。
//不断更新余图,增加流量 MAX_FLOW(s, t){ flow <- 0; WHILE(1){ FOR i <- 0 To n-1 st[i] <- false; //初始化 f <- dfs(s, t, INF); IF f == 0 THEN return flow; flow <- flow + f; } }
//找余图的增广路径,更新余图,并返回该路径的流量 DFS(v, t, f){ IF v == t THEN //到达汇点 return f; //dfs st[v] <- true; FOR i <- 0 To n e <- edge[v][i]; //s点连的边 k <- e.vertice; //e的出节点 IF(!st[k] && e.w > 0) //e.w是这条边的权值 d <- dfs(k, t, min(f, e.w)); IF d TEHN //更新正向边和反向边 e.w <- e.w -d; e.inverse_w <- e.inverse_w + d; return d; return0; }
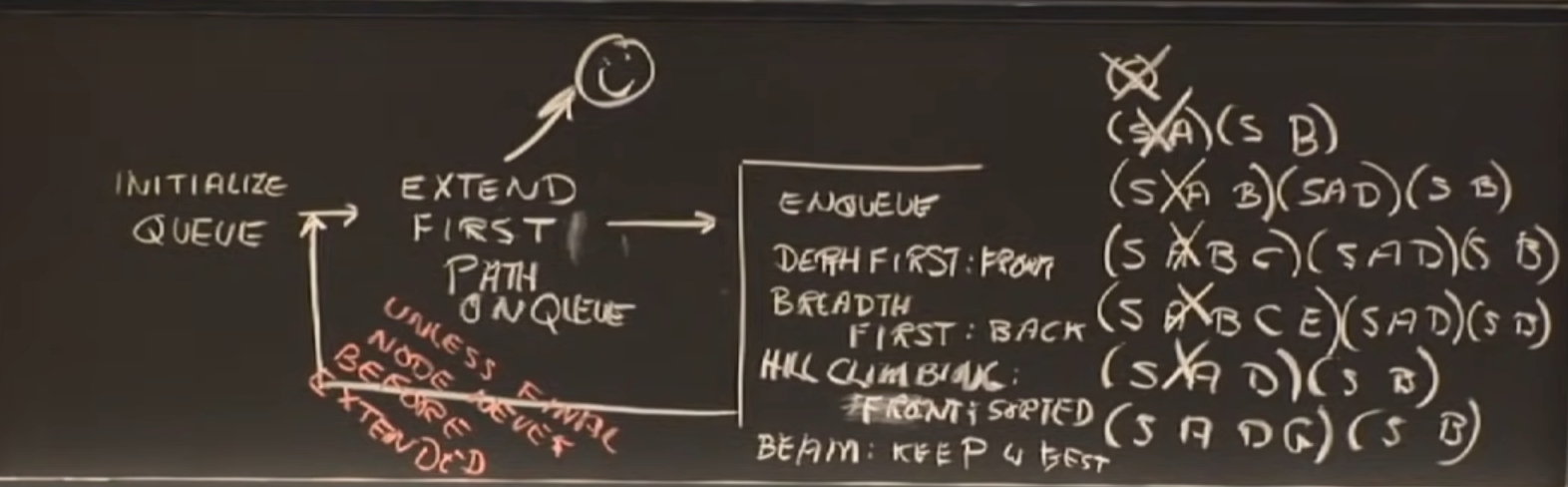
search can solve lots of different kinds of problems,比较常见的有组合优化问题,约束满足问题。举个例子就很容易理解了,背包问题,最短路问题,后面的小猫爬山习题就是组合优化问题,而八皇后,四色问题这种就属于约束满足问题。
对于组合优化问题,首先来看一下解空间的定义(●’◡’●), 然后具体的话,先看这个组合优化问题可不可能用dp和贪心整了,要是不行,就考虑搜索,而搜索其实就是 for these points in the solution space, choose a right search sequence that generates the search space which can cover the hole solution space and the elements in it exhaustedly. 但是也不能是爆搜,所以对于搜索,也是要有具体的一些优化方法的。
搜索的优化
搜索大概分为search for a good answer和search for the optimal answer。
对于搜索一个answer的情况大概有以下的讨论:
首先肯定是从爆搜开始优化,在歪果叫做British Museum algorithm,这个算法的消耗就和算法名字一样huge。
Hill-climbing searches work by starting off with an initial guess of a solution, then iteratively making local changes to it until either the solution is found or the heuristic gets stuck in a local maximum. There are many ways to try to avoid getting stuck in local maxima, such as running many searches in parallel, or probabilistically choosing the successor state, etc. In many cases, hill-climbing algorithms will rapidly converge on the correct answer. However, none of these approaches are guaranteed to find the optimal solution.
Branch-and-bound solutions work by cutting the search space into pieces, exploring one piece, and then attempting to rule out other parts of the search space based on the information gained during each search. They are guaranteed to find the optimal answer eventually, though doing so might take a long time. For many problems, branch-and-bound based algorithms work quite well, since a small amount of information can rapidly shrink the search space.
In short, hill-climbing isn’t guaranteed to find the right answer, but often runs very quickly and gives good approximations. Branch-and-bound always finds the right answer, but might take a while to do so.
而对于search for the optimal answer,我们关注的是how long have we traveled.可以利用branch and bound分支界限来最优化剪枝(mit这里应该是把branch and bound定义成best-first和剪枝),另外也可以通过启发式函数进行优化。而算法就可以看为branch&bound + extended list + admissible heuristic。
find a good answer考虑的是enqueued list, 而find an optimal answer考虑的是extended list.
A node is enqueued does not mean that it is extended. In fact, we can enqueue many times the same node, but with different distance value each time, they are just candidates for extension. And we just choose the shortest for extension.
differences between find a good path and find a best path.

to destination
can have
“stops”. According to Lemma 24.15 Path-relaxation property in CLRS, after each “relaxation” step, you get
and this value remains unchanged ever since. So after

)。Dijkstra会遍历所有节点的所有边,其实就是遍历所有边,有
这么多边,因此每一次更新小根堆排序的情况是
,一共最多